Si le processus reçoit sa source d’une table (ou d’un segment stratégique, dans les processus autorisant cette option), la fenêtre Effectif maximum de la cible suivante s’affiche :
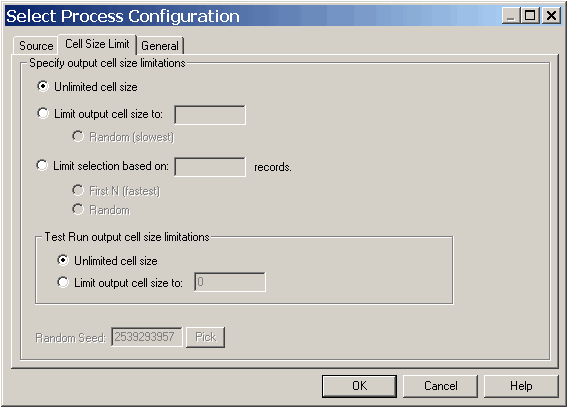
Cette fenêtre permet de préciser les limites que vous souhaitez appliquer à l’effectif de la cible générée. Les différences principales entre les options autres que Ne pas limiter effectif de cible sont leur impact sur les ressources et le nombre final d’enregistrements résultants générés lorsque la source de données n’est pas normalisée.
|
|
Ne pas limiter effectif de cible — retourne tous les identifiants répondant aux critères de requête ou de sélection sur l’onglet de ce processus. Il s’agit de l’option par défaut.
|
|
|
Limiter effectif de la cible à — retourne un nombre exact d’identifiants uniques, sélectionnés aléatoirement à partir de tous les identifiants répondant aux critères de votre requête. Entrez le nombre d’identifiants à retourner dans la boîte de texte. À l’aide de cette méthode, Campaign dédoublonne l’intégralité des identifiants avant la sélection aléatoire. Il ne conserve ensuite que le nombre d’enregistrements spécifié, de telle sorte qu’une liste composée d’identifiants uniques est retournée même lorsqu’il existe des doublons dans les identifiants.
|
|
|
Limiter sélection sur la base de — utilisez ces options pour permettre à Campaign de limiter la sélection des enregistrements répondant aux critères de votre requête. Ces options réduisent le temps et l’utilisation de ressources mémoire nécessaires à la sélection de l’ensemble final d’enregistrements, mais le résultat peut être inférieur au nombre d’identifiants uniques indiqué.
|
|
|
N premiers (plus rapide) — Campaign ne récupère dans la base de données que les premiers enregistrements répondant aux critères de votre requête. Avec cette méthode, Campaign cesse d’accepter les enregistrements dès réception d’un certain nombre d’enregistrements. Campaign dédoublonne ensuite ces identifiants ; si les données n’ont pas été normalisées, alors votre résultat final comprend un nombre d’enregistrements uniques inférieur. Cette méthode est plus rapide car la récupération des données demande moins de temps et elle utilise moins d’espace temporaire.
|
|
|
Aléatoire — Campaign reçoit, depuis la base de données, tous les enregistrements correspondant aux critères de votre requête, puis il sélectionne le nombre d’enregistrements de façon aléatoire. Campaign dédoublonne ensuite ces identifiants ; si les données n’ont pas été normalisées, alors votre résultat final comprend un nombre d’enregistrements uniques inférieur. Cette option emploie un volume d’espace temporaire réduit, car seuls les enregistrements sélectionnés aléatoirement sont récupérés et stockés par Campaign.
|