Wenn der Prozessseine Eingabe aus einer Tabelle (oder wenn die Option unterstützt wird – aus einem strategischen Segment) bezieht, wird das Fenster Max. Zellengröße angezeigt:
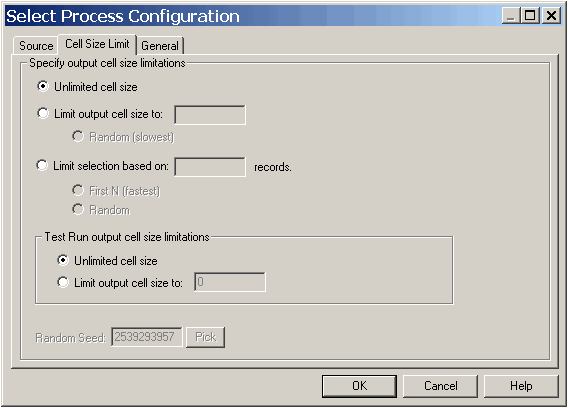
In diesem Fenster können Sie die Begrenzung der Ergebniszellengröße festlegen. Die Hauptunterschiede zwischen allen Optionen bis auf Unbegrenzte Zellengröße bestehen in der Auswirkung der Optionen auf Ressourcen und der Anzahl der Datensätze, die bei nicht einheitlichen Datenquellen ausgegebenen werden.
|
|
Unbegrenzte Zellengröße – gibt alle IDs zurück, die die Abfrage- oder Auswahlkriterien der Registerkarte dieses Prozesses erfüllen. Dies ist die Standardoption.
|
|
|
Max. Ergebniszellengröße begrenzen auf: – gibt eine genau festgelegte Anzahl von eindeutigen IDs aus, die aus allen IDs, die die Kriterien Ihrer Abfrage erfüllen, zufällig ausgewählt wurden. Geben Sie im Textfeld die Anzahl der IDs ein, die ausgegeben werden sollen. Mit dieser Methode entfernt Campaign die Doppelungen innerhalb des gesamten Satzes von IDs, bevor die zufällige Auswahl erfolgt. Anschließend wird nur die festgelegte Anzahl von Datensätzen beibehalten, sodass eine Liste von eindeutigen IDs ausgegeben wird, auch wenn in den ID-Feldern doppelte Einträge vorhanden sind.
|
|
|
Auswahl begrenzen basierend auf – Verwenden Sie diese Option, um die Möglichkeiten von Campaign bei der Auswahl von Datensätzen einzuschränken, die die Kriterien Ihrer Abfrage erfüllen. Mit diesen Optionen werden die für die Auswahl der endgültigen Datensätze benötigten Ressourcen Zeit und Speicherplatz reduziert, wobei möglicherweise weniger eindeutige IDs als festgelegt ausgegeben werden.
|
|
|
Ersten n (am schnellsten) – Campaign ruft nur die ersten n Datensätze aus der Datenbank ab, die die Kriterien Ihrer Abfrage erfüllen. Mit Hilfe dieser Methode nimmt Campaign keine Datensätze mehr an, sobald die Zahl von n Datensätzen erreicht ist. Anschließend entfernt Campaign die doppelten IDs. Wenn die Daten nicht normalisiert wurden, umfasst Ihr Endergebnis weniger als n eindeutige Datensätze. Dies ist die schnellste Methode, da für das Empfangen von Daten weniger Zeit und weniger temporärer Speicherplatz benötigt werden.
|
|
|
Zufällig – Campaign erhält von der Datenbank alle Datensätze, die die Kriterien Ihrer Abfrage erfüllen. Anschließend werden daraus zufällig n Datensätze ausgewählt und die doppelten IDs entfernt. Wenn die Daten nicht normalisiert wurden, umfasst Ihr Endergebnis weniger als n eindeutige Datensätze. Mit dieser Option wird der benötigte temporäre Speicherplatz reduziert, denn nur die zufällig ausgewählten Datensätze werden abgerufen und von Campaign gespeichert.
|