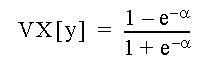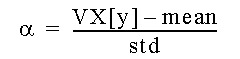
|
|
mean 및 std가 제공되는 경우 이 값은 각각 평균 및 표준 편차에 사용됩니다. 이러한 매개변수를 ROW 키워드와 함께 제공하는 경우 mean 및 std는 각 data 행의 평균 및 표준 편차를 지정하는 열일 수 있습니다. min 및 max가 열일 경우 열은 data 또는 스칼라(data의 해당 열에 있는 모든 값에 적용될 상수로 사용되는 단일 값 포함)와 같은 길이여야 합니다.
|
|
|
|
|
위에 언급된 상호 배타적 옵션을 제공하지 않은 경우 평균 및 표준 편차가 data에서 자동으로 계산됩니다.
|
|
|
같은 base_data 범위(예: 랩핑된 사용자 함수에서)를 사용하여 데이터를 정규화하려면 mean 및 std 상수를 만드십시오. 이 작업은 CONSTANT 매크로 함수를 사용하여 수행할 수 있습니다.
|
|
TEMP = NORM_SIGMOID(V1) 또는 TEMP = NORM_SIGMOID(V1,ALL)
|
|
TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. 각 열은 V1, V2 및 V3 열 컨텐츠의 정규화된 값을 포함합니다. 정규화에 사용되는 평균 및 표준 편차는 V1, V2 및 V3 열에서 계산됩니다.
|
|
각 열이 1-41 행의 값을 포함하는 TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. TEMP 열의 컨텐츠는 V1 열의 10-50 행에 대한 정규화된 값이고, VX 열의 컨텐츠는 V2 열의 10-50 행에 대한 정규화된 값이며, VY는 V3 열의 10-50 행에 대한 정규화된 값입니다. 정규화에 사용되는 평균 및 표준 편차는 V1-V3 열의 10-50 행에서 계산됩니다.
|
|
TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. 각 열은 V1, V2 및 V3 열 컨텐츠의 정규화된 값을 포함합니다. 정규화에 사용되는 평균 및 표준 편차는 V4 열에서 계산됩니다.
|
|
TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. 각 열은 V1, V2 및 V3 열 컨텐츠의 정규화된 값을 포함합니다. 정규화에 사용되는 평균 및 표준 편차는 V4-V8 열에서 계산됩니다.
|
|
TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. 각 열은 V1, V2 및 V3 열 컨텐츠의 정규화된 값을 포함합니다. 정규화에 사용되는 평균 및 표준 편차는 열마다 개별적으로 계산됩니다. 즉, V1 열에 대한 평균 및 표준 편차가 계산되고, V2 열에 대해 별도의 평균 및 표준 편차가 계산됩니다.
|
|
각 열이 1-41 행의 값을 포함하는 TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. TEMP 열의 컨텐츠는 V1 열의 10-50 행에 대한 정규화된 값이고, VX 열의 컨텐츠는 V2 열의 10-50 행에 대한 정규화된 값이며, VY는 V3 열의 10-50 행에 대한 정규화된 값입니다. 정규화에 사용되는 평균 및 표준 편차는 V1-V3 열의 10-50 행에서 계산됩니다. 정규화에 사용되는 평균 및 표준 편차는 열마다 개별적으로 계산됩니다.
|
|
TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. 각 열은 V1, V2 및 V3 열 컨텐츠의 정규화된 값을 포함합니다. 정규화에 사용되는 평균 및 표준 편차는 V4-V6 열을 사용하여 열마다 개별적으로 계산됩니다. 즉, V1 열의 정규화를 위해 V4 열에서 평균 및 표준 편차가 계산되고, V2 열의 정규화를 위해 V5 열에 대해 별도의 평균 및 표준 편차가 계산됩니다.
|
|
TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. 각 열은 V1, V2 및 V3 열 컨텐츠의 정규화된 값을 포함합니다. 정규화에 사용되는 평균 및 표준 편차는 V1, V2 및 V3 열에서 행마다 개별적으로 계산됩니다.
|
|
각 열이 1-41 행의 값을 포함하는 TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. TEMP 열의 컨텐츠는 V1 열의 10-50 행에 대한 정규화된 값이고, VX 열의 컨텐츠는 V2 열의 10-50 행에 대한 정규화된 값이며, VY는 V3 열의 10-50 행에 대한 정규화된 값입니다. 정규화에 사용되는 평균 및 표준 편차는 V1-V3 열의 10-50 행에서 계산됩니다. 정규화에 사용되는 평균 및 표준 편차는 V1-V3 열의 각 행에서 계산됩니다.
|
|
TEMP, VX 및 VY라는 세 개의 열을 새로 작성합니다. 각 열은 V1, V2 및 V3 열 컨텐츠의 정규화된 값을 포함합니다. 정규화에 사용되는 평균 및 표준 편차는 V4-V10 열에서 행마다 개별적으로 계산됩니다.
|
|
Copyright IBM Corporation 2015. All Rights Reserved.
|