|
|
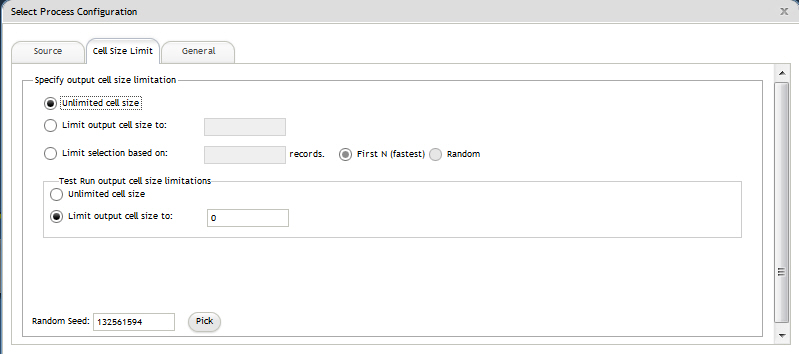
Ne pas limiter effectif de cible : renvoie tous les ID répondant aux critères de recherche ou de sélection. Cette option représente la valeur par défaut.
|
|
|
Limiter taille de la cible générée à : renvoie exactement le nombre d'ID uniques spécifié, sélectionnés de façon aléatoire parmi tous ceux qui répondent aux critères de recherche. Dans la zone de texte, saisissez le nombre maximum d'ID à renvoyer. Campaign déduplique l'ensemble complet des ID avant la sélection aléatoire, puis conserve uniquement le nombre d'enregistrements spécifié, de façon à ce qu'une liste d'ID uniques soit renvoyée, même lorsque des doublons existent dans les zones d'ID. Cette option utilise une grande quantité d'espace temporaire et dure très longtemps, car tous les ID doivent être récupérés sur le serveur Campaign. Utilisez uniquement cette option si les données ne sont pas normalisées dans la zone d'ID et qu'il est important que N enregistrements soient renvoyés.
|
|
|
Limiter sélection sur la base de : utilisez cette option pour limiter les enregistrements qui répondent à vos critères de recherche. Cette option réduit le temps et la mémoire nécessaires pour sélectionner l'ensemble final d'enregistrements. Toutefois, elle peut entraîner l'obtention d'un nombre d'ID inférieur au nombre d'ID uniques spécifié.
|
|
|
N premiers (plus rapide) : Campaign extrait de la base de données uniquement les N premiers enregistrements répondant à vos critères de recherche. Campaign déduplique ensuite ces ID. Si les données ne sont pas normalisées, le résultat final contient moins d'enregistrements que le nombre requis d'enregistrements uniques. Cette méthode est la plus rapide car la récupération des données prend moins de temps et elle utilise moins d'espace temporaire.
|
|
|
Aléatoire : Campaign extrait de la base de données tous les enregistrements répondant à vos critères de recherche, puis sélectionne de façon aléatoire le nombre d'enregistrements requis. Campaign déduplique ensuite ces ID. Si les données ne sont pas normalisées, le résultat final contient moins d'enregistrements que le nombre requis d'enregistrements uniques. Cette option utilise moins d'espace temporaire, car seuls les enregistrements sélectionnés de manière aléatoire sont extraits et stockés par Campaign.
|
|
Copyright IBM Corporation 2015. All Rights Reserved.
|