|
|
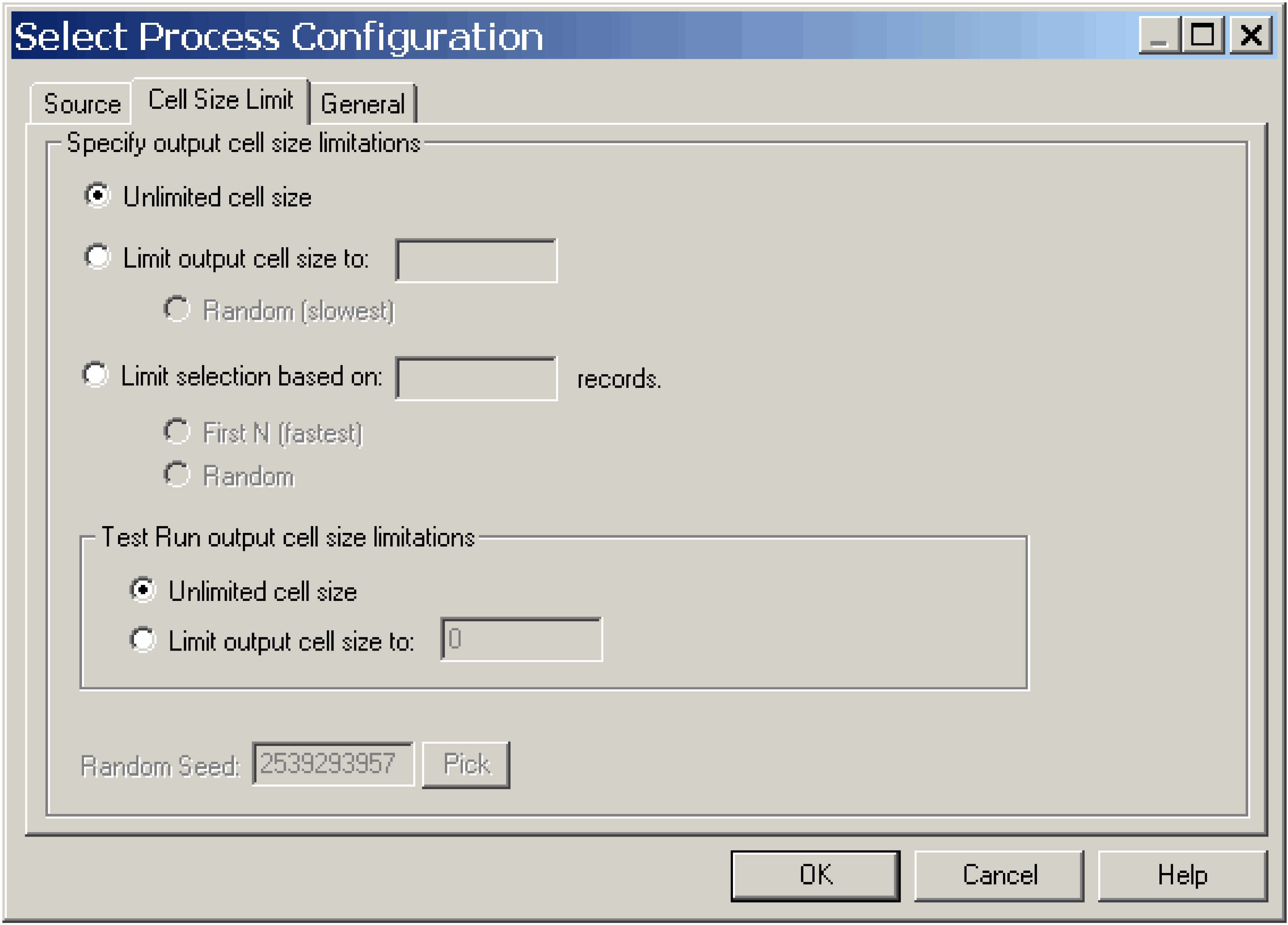
Dimensioni cella illimitate: restituisce tutti gli ID che soddisfano la query o i criteri di selezione sulla scheda di questo processo. Questa è l'opzione è quella predefinita.
|
|
|
Limita dimensioni della cella di output a: restituisce un numero specifico di ID univoci, selezionati in modo casuale tra tutti gli ID che soddisfano i criteri della propria query. Inserire il numero di ID che si vuole vengano restituiti. Campaign elimina i duplicati nella serie completa di ID prima della selezione casuale, poi mantiene solo il numero specificato di record, di modo che come risultato venga restituito un elenco di ID univoci anche quando esistono dei duplicati sui campi ID.
|
|
|
la selezione dei record con questa opzione utilizza un grande quantitativo di spazio temporaneo e richiede più tempo, dato che tutti gli ID devono essere recuperati dal server Campaign. Servirsi di questa opzione solo quando i dati non sono normalizzati sul campo ID e se è importante che come risultato vengano presentati esattamente N record.
|
|
|
Limita la selezione sulla base di: servirsi di queste opzioni per limitare i record Campaign che soddisfano i propri criteri. Queste opzioni riducono le risorse di tempo e di memoria usate in fase di selezione del set finale di record, ma possono portare a meno risultati rispetto al numero di ID unici indicato.
|
|
|
Primi N (più veloce): Campaign recupera dal database solo i primi record che soddisfano i criteri della query. Campaign non accetta più record quando si è raggiunto il numero di record specificato. Campaign poi elimina i duplicati tra questi ID; nel caso in cui i dati non siano stati normalizzati, il risultato finale contiene meno record univoci. Si tratta del metodo più rapido in quanto il recupero dei dati richiede meno e usa meno spazio provvisorio.
|
|
|
Casuale: Campaign recupera dal database tutti i record che soddisfano i criteri della query, quindi seleziona in modo casuale un numero di record da questi record. Campaign poi elimina i duplicati tra questi ID conservati; nel caso in cui i dati non siano stati normalizzati, il risultato finale conterrà meno record univoci. Questa opzione richiede meno spazio temporaneo, in quanto solo i record selezionati in modo casuale vengono recuperati e conservati da Campaign.
|
|
Copyright IBM Corporation 2012. All Rights Reserved.
|